今天我听了 lenny 和 Claude Code 负责人 Boris Cherny 的谈话,作为一个在 Meta/Ins 等公司产出最高的程序员之一,他已经一年都没有亲自写和手改过代码了,全都是用 Claude Code 写的,而他依然是产出最高的程序员之一。这太令人震惊了。
这将会为软件行业和世界带来怎样的变化,AppStore 主导的 App 模式是否还会是未来。人人都能写代码之后,软件产品和服务一定会井喷,它的价值和价格肯定会降低的。那么在行业中的我们,该怎么办才能不错过这个时代。
正好 Andrej Karpathy 昨天也发了几条关于这个事情的推文,值得一看。
推文 1
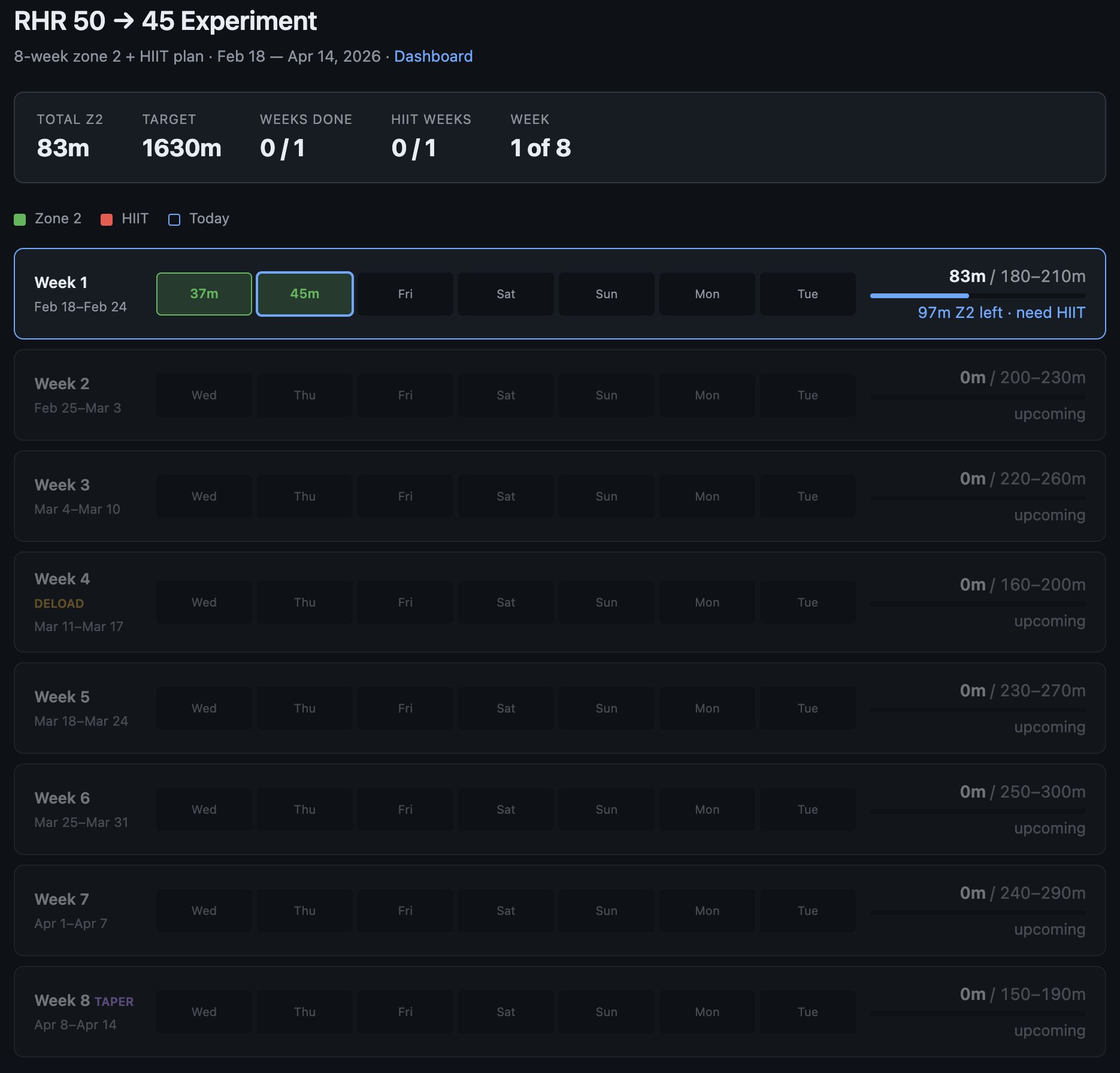
我对即将到来的“高度定制化软件”时代会是什么样子非常感兴趣。举个今天早上的例子——我最近在有氧训练上有点松散,所以我决定做一个更严肃、更有纪律的实验:在 8 周内把静息心率从 50 降到 45。主要方法是争取在 Zone 2 有氧上达到一定总分钟数,并且每周做 1 次 HIIT。1 小时后,我就 vibe coded 了一个超定制的仪表盘,专门用来追踪这个非常具体的实验。Claude 需要逆向 Woodway 跑步机的云 API 来拉取原始数据、处理、过滤、调试,并做一个 Web UI 前端来追踪实验。整个过程并不完全顺滑,我也得自己发现并要求修 bug,比如它把公制和英制单位搞错了,还把日历里的日期和星期对应搞乱了等等。但我仍然觉得大方向很清楚:1)这种事情永远不会(也不应该)有一个专门的 App Store 应用。我不该为了这类需求去找、下载并使用某种“Cardio experiment tracker”,因为这东西不过是约 300 行代码,LLM agent 几秒钟就能给你。面对 LLM agent 可以现场即兴、只为你生成应用的现实,“从长尾离散应用里挑选”的 App Store 这种概念显得不对劲也过时了。2)其次,这个行业必须重构为一组具备 agent 原生人体工学的传感器与执行器服务。我的 Woodway 跑步机就是一个传感器——它把物理状态转成数字知识。它不该维护一套面向人类阅读的前端,我的 LLM agent 也不该去逆向它;它应该直接是一个能被 agent 轻松使用的 API/CLI。整个行业在这方面推进得太慢了,我有点失望(也直接拖慢了我的节奏)。99% 的产品/服务还没有 AI-native CLI。99% 的产品/服务还在维护 .html/.css 文档,仿佛我不会立刻把整页复制给 agent 去办事一样。它们在网页上给你一堆说明,让你打开这个 URL、点那个按钮来完成某件事。都 2026 年了。我是计算机吗?你去做啊。或者让我的 agent 去做。总之,今天这个随机需求 1 小时就完成了(两年前大概要 10 小时),我确实印象深刻。但更让我兴奋的是去思考:这本来应该顶多 1 分钟。要做到 1 分钟,需要哪些前提?这样我只要说一句“Hi can you help me track my cardio over the next 8 weeks”,在一个非常简短的问答之后,应用就能起来。AI 已经拥有大量个人上下文,会自动补齐额外数据,会引用和搜索相关技能库,并维护我所有小应用/自动化。TLDR:从一组离散应用里挑选的“App Store”概念本身正越来越过时。未来是由 AI-native 传感器与执行器服务,通过 LLM 胶水编排成高度定制、短暂存在的应用。只是它还没真正到来。 https://x.com/karpathy/status/2024583544157458452
推文 2
我觉得这组反应本质上仍然根植于一种“软件稀缺”心态。两年前 AI 还把自动补全做得一塌糊涂,今天它已经几乎能一把做出浏览器和 C 编译器。再过 2 年呢?10 年?20 年?软件会便宜且充沛到离谱,以至于按今天这个意义上的离散“App”将不再合理。它只是一条条为超具体目的临时组装出来的代码路径,执行一次后就被删除。你不需要懂任何东西,也不需要在这件代表你发生的事情上施加任何创意指挥。如果说今天的软件是用代码砖块砌出来的城堡,那这更像是一锅正在沸腾的代码汤。我不确定它是否会完全按这个方向展开,过程会是混合的、渐进的等等,但在原则上它可能会变得非常怪异。 https://x.com/karpathy/status/2024933972523057610
推文 3
AI psychosis 的更高层级与今天的“App Store”不兼容。 https://x.com/karpathy/status/2024936435816796165